Earth system modeling becomes more and more data-limited, both in terms of data volume and throughput. As part of a common vision for exascale Earth system modeling in the Helmholtz Association, the activity group Exascale Workflow Scalability rethinks traditional ways of storing, analyzing, and sharing data to enable scalable and performance-portable solutions for big data workflows on modern supercomputing architectures. Novel object storage concepts allowing for fast data access, cloud solutions for data services, and data mining and ML methods to automatically annotate and enrich data with descriptive metadata will be further explored.
Storage concepts for exascale
Facing the ever-growing storage demands from ESM output data in the km range, paired with the necessity of post-processing, analyzing, sharing and publishing of such data or its sub-datasets, new concepts for effective storage and staging will be investigated:
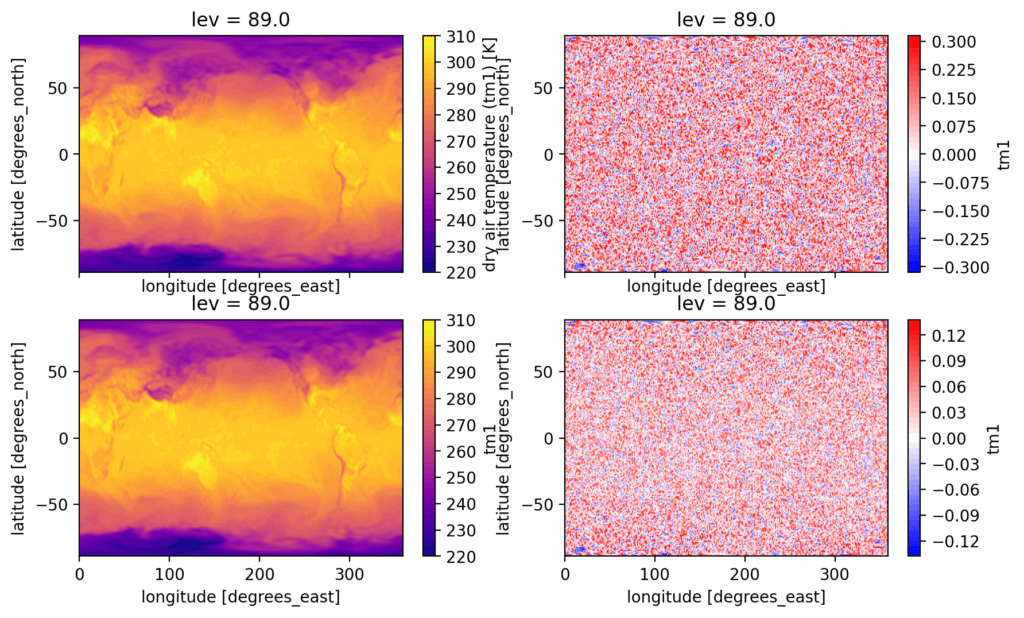
Lossless / Lossy data compression
Data compression is a traditional way to reduce large datasets. Ideally, data compression and decompression is fast and reliable in the sense of bit-wise reproducibility of original data. Depending on the precision of the data produced, but also on the intention of its usage, lossy data compression can be considered to reduce data size. We will explore here compression options with netCDF incl. more suited backend data formats such as the Zarr data format. The Zarr data format will be supported by the official netCDF format in the near future and is optimized for cloud storage options like s3 object storages. Further, it allows more easily to exchange of compression algorithms and enables fast testing of different algorithms.
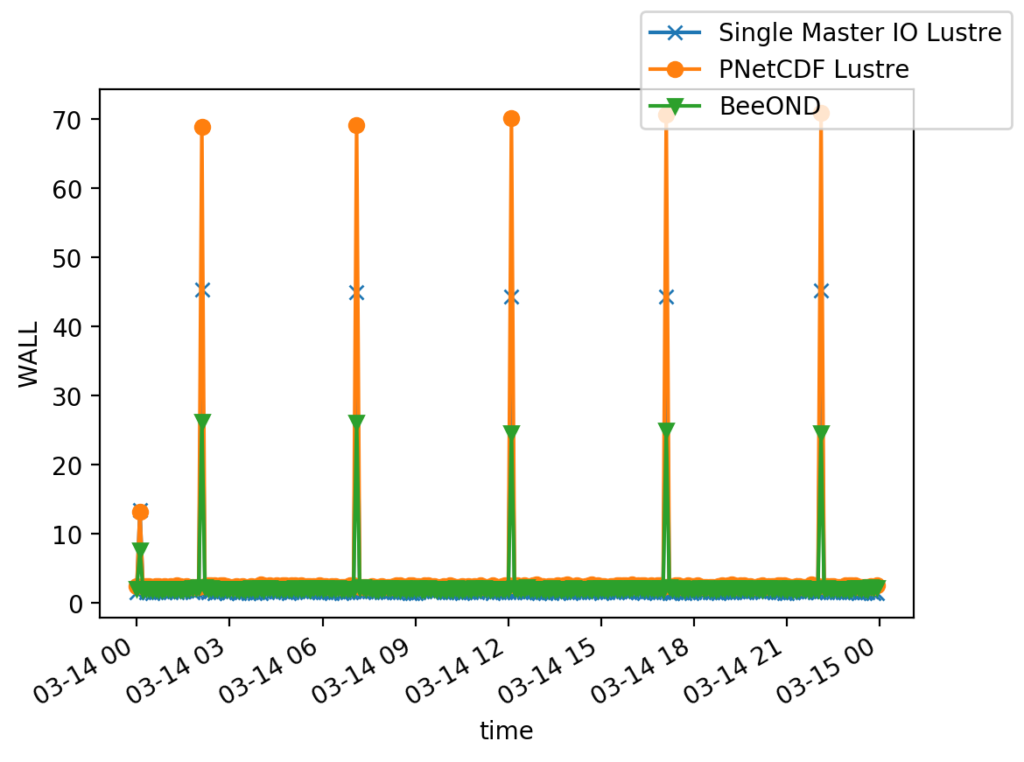
SSD-based fast storage tiers (node-local or cache-based layer)
The High Performance Storage Tier (HPST) at JSC ( https://apps.fz-juelich.de/jsc/hps/juwels/cscratch.html ) acts as an NVMe-based cache layer on top of JUST, offering fast access to data stored in the SCRATCH file system. This added storage sub-system further closes the gap between the GPFS file system on one hand and the compute systems on the other. Data analysis and I/O-intensive applications, in particular read-intensive AI workloads, can greatly benefit from staging data to a faster storage tier. We will here explore the potential benefits of such SSD-based storage layers, either on cache or node-local, for typical ESM data workflows.
Node-local approaches allows for decentralized output generation of climate simulations. Each node has a local storage device which can be used for write and read operations. The output will then be merged in a concurrent process. The “Hochleistungsrechner Karlsruhe” (HoreKa) at KIT supports this on-demand filesystem using BeeOND (https://www.nhr.kit.edu/userdocs/horeka/filesystems/#beeond-beegfs-on-demand). The file system is created during job startup and purged after your job. BeeOND/BeeGFS can be used like any other parallel file system. Tools like cp or rsync can be used to copy data in and out.
Data staging and file size handling, HDF cloud and object storage applications
Intelligent ways of staging data on different layers of the HPC storage systems can greatly help to accelerate data access. Various data access patterns lead to notable differences in access time, which can possibly overcome by optimizing file sizes, storage formats and its chunking. Starting from the concept of DestinE data bridges, we will explore FDB to handle ESM data beyond ECMWF’s IFS model. Recommendations for file sizes and chunking will be developed as well as alternatives to netCDF (e.g. data cubes and Zarr files) will be investigated.
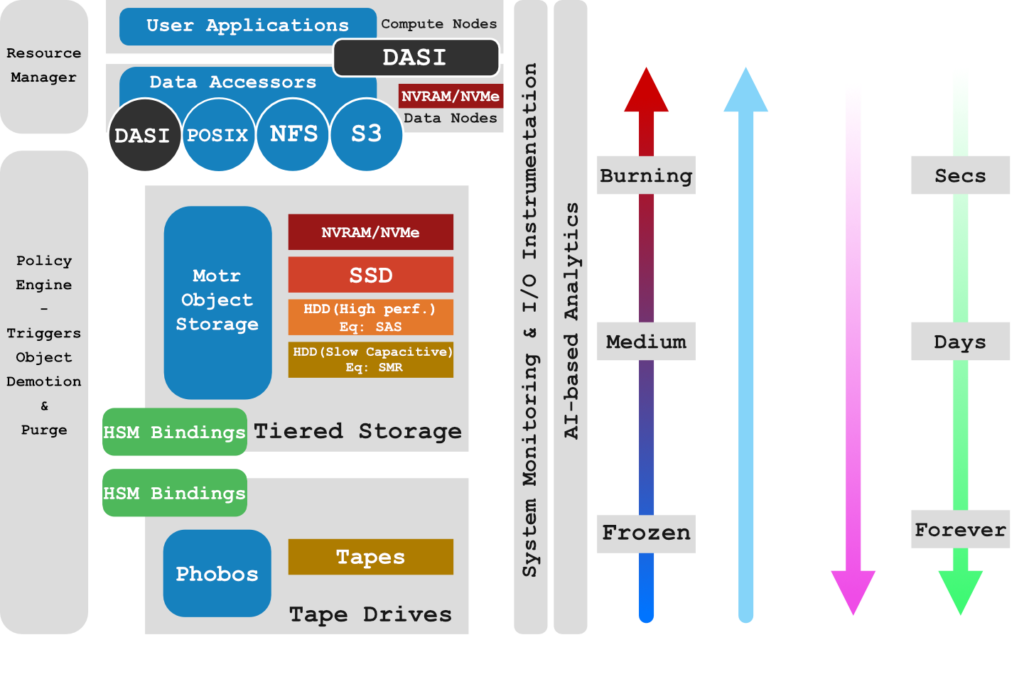
IO-Sea involvement (Data Nodes)
Credit: https://iosea-project.eu/
The IO-SEA project ( https://iosea-project.eu/ ) aims to provide a novel data management and storage platform for exascale computing based on hierarchical storage management (HSM) and on-demand provisioning of storage services. We will reach out to the IO-Sea project to find optimal solutions in the ESM context.
Data services and exchange
HPC and data centers are facing increasing demands for data access from automated services, either from other centers hosting portals to federated data repositories or from web users worldwide. This poses new challenges for administration, transfer security, and accounting.
Pseudo-operational automated services
There is growing need to access ESM data residing on the HPC systems from anonymous users or user groups. Typically, access is granted for remote servers without knowing the authenticity of the user. Such activity can put considerable workload on the system, which requires for specification of rules and policies. One prominent example in the ESM community would be the CI/CS system buildbot. HPC administrators and ESM scientists will rethink responsabilities and firewall settings and define service accounts which can deal with the demands of such untrustable users.
Site-to-site data transfers
Often, large amounts of ESM data need to be transferred between a limited number of HPC sites. We will ease such transfers by facilitating ssh and firewall settings for trusted sites, explore usage of uftp and other parallel transfer methods, and set up a document for best practices.
Postprocessing and analysis workflows
To avoid data movement, data analysis preferably is performed where the data resides. Such analysis – including postprocessing – can be time-consuming and provoke substantial computational overhead. Exascale readiness needs to be accessed for typical analysis workflows including tools, job submission, and ML applications.
Smooth transition between interactive and batch jobs
Various ML applications perform statistical analyses using randomized analyzing techniques. Such a workflow asks for flexible job chains including interactive and batch submissions. We will further develop such options with slurm and JupyterLab and demonstrate theit applicability to workflows relevant for ESM.
Exascale readiness of postprocessing tools
Many of the existing postprocessing tools have not been written with exascale applications in mind. We will evaluate existing tools and come up with propositions for improvement.
Reach out to ESMVal community
For years, the ESMVal community established big data workflows and analysis in ESM. With ESMValTool ( https://www.esmvaltool.org ), they developed a community diagnostic and performance metrics tool for routine evaluation of Earth system models in CMIP. With this activity, we want to reach out to the ESMVal community to learn from their experience and exchange ideas.